100 Billion Tokens
Posted on April 27, 2026 • 17 min read • 3,549 wordsThe Curious case of 100 Billion Tokens.
Previously on the e-INFRA Blog …
In our previous post, we described how we adopted the SGLang inference framework and started running a few more advanced models, such as the full version of DeepSeek R1. Since then, we improved our hardware – serving from two NVIDIA DGX machines, a B200 and a B300, with 1.4 TB and 2.1 TB of GPU memory respectively. We adopted new open-weighted models. We run, we served, we sometimes failed, and today, the LLM service at CERIT-SC has processed 100 billion tokens.
I. The Hundred Billion
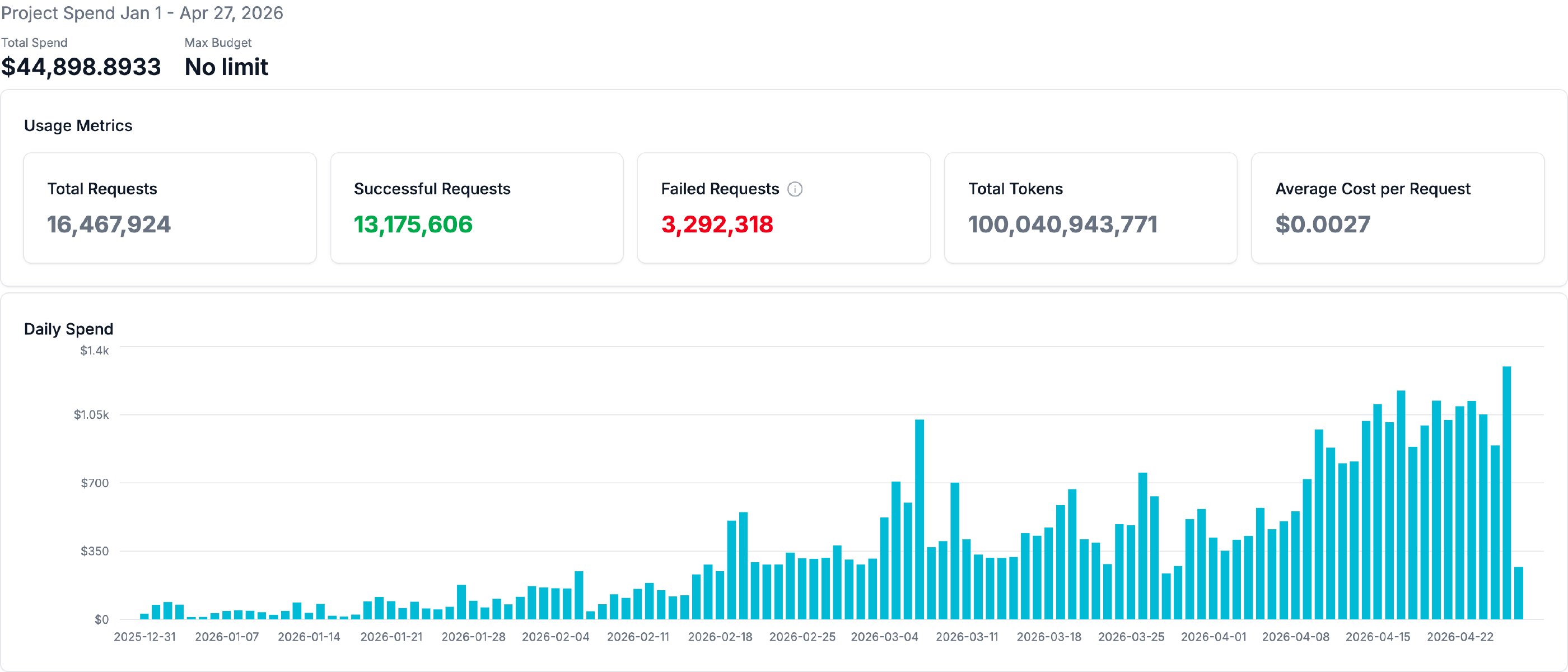
The vast majority of these were input tokens — a fact which deserves, and shall presently receive, a proper explanation. There is, in fact, rather a lot worth explaining.
The kettle is on. We may as well begin.
II. Why Input Dominates: A Short Detour Through Prefill and Decode
Those new to operating language models at scale are sometimes surprised to discover that their machines spend most of their time reading, and only a modest fraction writing. The asymmetry is not accidental. It is, in fact, baked into the architecture of inference itself.
A modern transformer processes a request in two distinct phases. The first is prefill: the model ingests the entire prompt at once, in parallel, computing the attention state across all input tokens simultaneously. This phase is compute-bound — limited by the raw floating-point capability of the GPU, and remarkably fast on a per-token basis. A modern accelerator can plough through tens of thousands of input tokens in the time it takes to clear one’s throat.
The second phase is decode: the model generates output tokens one at a time, each new token requiring a full pass through the network conditioned on every token that came before. This phase is memory-bandwidth-bound — limited not by how fast the GPU can compute, but by how fast it can move weights and KV-cache entries through its memory subsystem. Decode is, in a word, slow. Per token, it is typically an order of magnitude slower than prefill.
The natural consequence: a single user turn might consist of forty thousand input tokens and eight hundred output tokens. The user perceives this as “asking a question and getting an answer.” The hardware perceives it as “an enormous prefill followed by a modest decode.” Both views are correct; only the second pays the bills.
The evidence from our last month of traffic confirms the pattern with some emphasis. Across our serving fleet, prompt tokens outweighed completion tokens by roughly an order of magnitude. GLM 5.1 ran at a 17.3× input-to-output ratio. Kimi K2.6 at 18.5×. These are not anomalies. They are the fingerprint of how modern language models are actually used — a topic to which we shall return when we discuss the Deatheaters.
A well-served cluster, then, must be competent at both phases of inference. It must have the compute to absorb large prefills without complaint, and the memory bandwidth to sustain decode at acceptable rates. Excellence in one and mediocrity in the other produces a serving experience that is either snappy and incoherent or thorough and glacial. Neither is what one wants.
III. The Residents of the Establishment
Let us turn to the matter of which models we currently host, and on what hardware. We shall introduce them in roughly the order of their temperament.
Qwen 3.5 — the dependable workhorse, good coder, whose virtues are sometimes overlooked precisely because it never causes trouble. It runs in FP8 quantization (which, despite occasional confusion on the matter, is not the model’s native precision — it is a deliberate quantization choice, executed carefully). It resides on two B300 GPUs, sustains a peak throughput of 2,077 tokens per second, and tops out at 22 concurrent requests. Reliable, unfussy, occasionally underappreciated.
Kimi K2.6 — and here we must pause for a story. We deployed Kimi K2.6 on the day of its release. Not the week of, not the month after the dust had settled — the day. This is what is known in the trade as a 0-day deployment, and it brings with it the predictable consequences: early instabilities, configuration surprises, and the occasional component behaving in ways its authors had not entirely anticipated. Most of these have since been resolved or domesticated, with one notable holdout: the tool parser.
A brief digression, since the matter is important. A tool parser is the component responsible for extracting structured tool and function calls from the model’s free-form output stream. When a model emits something like <tool_call>{"name": "search", "args": {...}}</tool_call>, it is the parser’s task to recognize the boundary, extract the structured payload, and forward it to the agent’s execution layer. When the parser misreads a token boundary, mishandles a special marker, or becomes confused by an unfamiliar format variation, the agent silently fails — or, more troublingly, executes the wrong action with the right confidence. Every agentic workflow in modern existence — coding assistants, research agents, anything that calls functions — sits on this thin and surprisingly fragile layer of parsing logic. A subtly broken parser produces the kind of bug that appears, to the user, as the model “having a bad day.” It is, with regrettable consistency, never the model.
Kimi runs on four B300 GPUs, sustaining peak throughput of 1,670 tokens per second and reaching a maximum of 74 concurrent requests, and queue depths that have at times reached 48 — a figure to which we shall return shortly.
DeepSeek V3.2 — currently in residence and shortly to retire in favor of the forthcoming DeepSeek V4 Pro. It runs on the largest hardware footprint of any of our models: eight B200 GPUs. Peak throughput 2,022 tokens per second, maximum 54 concurrent requests. A transition we await with interest.
GLM 5.1 — the unusual case, running in NVFP4 quantization where its peers run FP8 or native. It resides on two B300 GPUs, sustains peak throughput of 1,395 tokens per second, and reaches a maximum of 36 concurrent requests, with queue depths sometimes reaching 99. That last figure is not a typo. GLM, as we shall see, has a clientele of conspicuous patience.
Alongside these principal residents, we host a small cohort of lighter-duty models — Qwen3.5-122B, GPT-OSS-120B, Mistral Small 4, and others — which serve more conversational workloads without ceremony or incident. They are the well-behaved guests who never require the establishment’s full attention, and we are grateful for them.
IV. The Serving Stack and Its Theatre
It would be misleading to suggest that the foregoing operates frictionlessly. Serving open-weights models at production quality is not, in 2026, a solved problem. It is a moving target on a moving platform, and the platform is moving rather faster than the target.
We use both vLLM and SGLang, depending on the model and the moment, and each brings its own collection of behaviours one must learn to anticipate.
vLLM emits its reasoning output under the field name reasoning, where LiteLLM — sitting one layer up in our serving topology — expects reasoning_content. A small naming mismatch, with surprisingly far-reaching consequences for any downstream tooling that cares about the distinction (which is, increasingly, all of it). We work around the discrepancy. vLLM also has notable troubles with reasoning content itself: when serving Kimi, it occasionally emits sequences of !!! into the streamed reasoning channel — a contribution which, we feel safe in saying, was not requested by the model and is not appreciated by the user. In our specific configuration, vLLM has further proven measurably slower than SGLang for the workloads we serve — not by a small margin, and not for reasons we have fully diagnosed. The investigation continues, with the patient resignation of those who have done this sort of investigation before.
SGLang, for its part, has its own and rather more theatrical failure modes. The tool parser — the same component discussed earlier — is a persistent source of operational interest. We see tool calls leaking into reasoning output, and reasoning leaking into tool calls, in roughly equal measure. The model emits a perfectly formed tool invocation; the parser, in a moment of confusion, treats it as part of the chain-of-thought and presents it to the user as commentary. Or precisely the inverse: a stretch of internal reasoning is mistakenly classified as a tool call and dispatched to the agent, which finds itself executing nonsense. Neither variety improves the user experience.
SGLang also, on certain occasions, crashes outright, or — more interestingly — gets stuck in a state from which only intervention will release it. These events are gracefully rare, but not so rare that we have stopped noticing.
A further phenomenon worth reporting is what we have come to call, with no great originality, model looping: the situation in which a model becomes enamoured of a particular phrase, sentence, or paragraph and proceeds to emit it again, and then again, and then once more for good measure, in apparent defiance of every signal that this is not what was wanted. We have witnessed this most reliably with SGLang, though we have no firm reason to believe vLLM is structurally immune. The consequences range from the merely tedious to the operationally expensive — a looping model, left unchecked, will happily consume its entire output budget repeating the same eight tokens until something intervenes. Worse, it does so while holding its full share of the KV cache — which, on a busy serving node, effectively means no other requests are being served until the looping one concludes.
Our current intervention is, frankly, blunt. We cap output length at 32K tokens, which ensures that even a determinedly looping model will eventually run out of rope and stop. In the worst cases — those models or workloads with a particular tendency toward circular output — we also inject a presence_penalty parameter into the request, which discourages the model from revisiting tokens it has already emitted. This is, we acknowledge, a coarse instrument applied to a subtle problem. One would naturally prefer to use repetition_penalty, which is conceptually better suited to the task — but SGLang’s implementation of that parameter has, in our testing, no observable effect. We have settled, accordingly, on what works rather than what was advertised.
We mention these difficulties not in complaint but as honest reportage. Anyone running production inference at this scale is fighting some version of the same dragons, and the appropriate response is fellowship rather than alarm. The dragons are, on balance, slowly becoming smaller.
V. When the Floodgates Opened: Scale and Saturation
For some considerable time we maintained the position that 24 parallel requests marked the boundary between comfortably serving researchers and what might politely be termed large-scale serving waters. The figure was somewhat arbitrary, somewhat empirical, and entirely correct in spirit: above it, the operational character of the work changes. Queues form. Latencies stretch. The phrase “we should probably look at the dashboards” enters the working vocabulary more frequently than one might wish.
Then came the first day of Kimi K2.6.
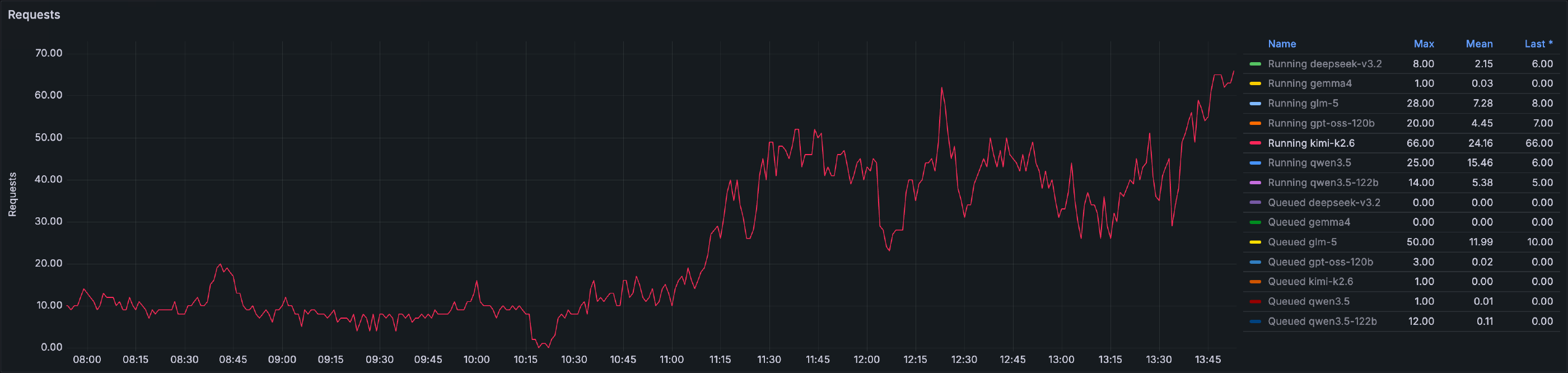
Seventy concurrent requests at peak. Queue depths reaching forty-eight at their worst. Throughput held; latency did not. Every response elongated in proportion to the collective enthusiasm, and the system performed exactly as it had been designed to perform — which is to say, slowly but reliably, save for those whose place in the queue exceeded the twenty-minute client timeout. Those, we regret to report, were quietly dropped on the floor.
GLM 5.1 has produced its own moments of quiet operational interest. Queue depths have reached 99 requests during peak periods, while throughput remained respectable and the patience of the user base, somewhat less so. There is, we have observed, a particular variety of researcher who regards a deep queue not as an obstacle but as confirmation that they have chosen the right model.
A small observation seems in order. Enthusiasm, when sufficiently parallel, becomes its own form of denial-of-service. The remedy is rarely to discourage the enthusiasm — that would defeat the purpose of the establishment entirely. One simply provides more hardware, or more queue, or, in the absence of either, more philosophical composure. The numbers in aggregate suggest that we are operating near the edge of capacity during peak hours: a position we view with a mixture of professional satisfaction and mild apprehension, in roughly equal proportion.
VI. The Deatheaters
We owe the reader an explanation, at last, of where the hundred billion tokens went. The answer involves a phenomenon we have come to call, with a certain dry affection, the Deatheaters: those modern agentic tools — Claude Code chief among them, with its various imitators and descendants close behind — whose appetite for tokens is, by any historical standard, prodigious.
The mechanics are worth setting out plainly. Each turn of an agentic session typically:
resends the entire conversation history; includes the full inventory of tool definitions, frequently dozens of them, regardless of which are relevant to the immediate task; reads whole files into context, sometimes the same file repeatedly across successive turns; performs multi-step reasoning in which each intermediate step is another full round-trip through the model; and allows context to grow monotonically until compaction kicks in, at which point it begins growing again from a slightly compressed baseline.
The cumulative effect is, to put it mildly, expansive. A single morning of “fix this bug across the codebase” can quietly account for several million tokens before lunch. Multiply by a busy researcher having a productive week, and the matter of where one hundred billion tokens went stops looking quite so abstract.
The numbers from last month make the pattern visible with some emphasis. The median (p50) prompt tells one story; the 95th percentile (p95) tells quite another:
| Model | p50 prompt | p95 prompt |
|---|---|---|
| Qwen 3.5 | 1,100 | 33,958 |
| Kimi K2.6 | 2,179 | 99,746 |
| GLM 5.1 | 709 | 90,351 |
| DeepSeek V3.2 | 879 | 23,776 |
| GPT-OSS-120B | 193 | 2,842 |
The contrast tells the whole story. The typical request is modest — a few hundred to a couple of thousand tokens, the natural shape of a question politely asked. The 95th-percentile request, for the agentic models, runs into the tens or hundreds of thousands. The gap between p50 and p95 is the Deatheater effect made visible: a relatively small number of agentic sessions consume the overwhelming majority of input tokens served.
The contrast with GPT-OSS-120B — p95 of just 2,842 — is instructive. That model is used conversationally rather than agentically, and its appetite reflects the difference. One might describe it as the well-mannered guest of the establishment, capable of an interesting conversation without first requiring the entire library to be brought into the parlour.
This is not, to be clear, a complaint. The Deatheaters are doing useful work — important work, in many cases. They are simply doing it expansively, and we mention the appetite because it is responsible for the lion’s share of where our hundred billion tokens went. A proper accounting requires acknowledging where the food was eaten.
VII. The Three-Layered Economics
We arrive at the section in which the household books are opened. There is, we should note in advance, more than one ledger at work here, and the picture changes considerably depending on which one is consulted. We shall consult them in order.
Movement One — The Price Tag
We virtually charge what Chinese providers charge for these same models served from their countries of origin. Kimi at $0.60 per million input tokens, GLM at $0.60, DeepSeek at $0.28, Qwen at $0.26.
Last month, our published rates produced approximately $25,800 in user-facing accounting against the traffic served. A useful reference point, and a number worth remembering: the researchers know what these tokens cost at their origin.
Movement Two — The Hardware Reality
The actual cost of serving these tokens is, regrettably, another matter entirely. The establishment runs on hardware that was not provided gratis. Two DGX systems at approximately $500,000 each, totaling $1,000,000. Add 20% for operational overhead — power, cooling, the appropriate share of staff time, the assorted indignities of running production hardware — and one arrives at $1,200,000. Amortized over a three-year service life, this works out to approximately $33,300 per month.
Last month we recovered $25,800 against $33,300 of cost. Roughly 77 cents on the dollar. By any conventional standard of unit economics, the operation is a polite financial embarrassment — the kind of arithmetic one does not bring up at the institute’s annual review without surrounding context. The federation absorbs a subsidy of approximately $7,500 per month to keep the service running at its current pricing.
So: a household running at a modest loss, charging the going rate, absorbing the difference. One can see how this would not, on its own, justify the operation.
And then we open the third ledger.
Movement Three — The Point
The prices in Movement One are a reference, not a realistic alternative. The Czech National Cyber and Information Security Agency — NÚKIB — has restricted the use of models hosted in China for institutional and sensitive workloads. The “cheap option” researchers see priced at $25,800 is, for most public-sector and for any workload involving sensitive data, not legally available. They can see the price. They cannot use the service.
The realistic alternative is the Western commercial market — Anthropic, OpenAI, and similar — at premium-tier rates. The same traffic, priced at Anthropic Sonnet-equivalent rates, would have cost researchers approximately $137,900 last month.
Against that baseline, the federation absorbs its $7,500 monthly subsidy and saves the institution something on the order of $104,000 every month. The annual figure approaches $1.25 million — which is, by a coincidence we find pleasing, roughly the entire amortized hardware cost of the operation, recovered each year through the simple expedient of not sending the money outside the federation.
There is a further point that deserves to be surfaced explicitly. The open-weights models we serve — Kimi, GLM, DeepSeek, Qwen — are themselves of Chinese origin. The NÚKIB restriction concerns hosting location and data sovereignty, not model provenance. Running these models on hardware that is, admittedly, not European in origin — but which sits on European premises, operates under European jurisdiction, and lets no data leave its boundaries — is precisely the arrangement the restriction is designed to encourage. The data stays where it was sent. Nothing leaks.
We are not, in other words, working around the rules. We are the architecture the rules presume.
The household books, in summary, only appear poorly kept until one understands which ledger one is supposed to be reading. Read from the user-facing ledger, the prices are commercial-equivalent. Read from the operations ledger, the service runs at a modest subsidy. Read from the institutional ledger, the federation saves over a hundred thousand dollars every month while keeping its data inside its own borders. Three ledgers, three pictures, and only one of them is the picture that matters.
VIII. Bring Your Own Hardware
The invitation, plainly extended.
Researchers and groups who own suitable GPU hardware are most welcome to connect it to the CERIT-SC LLM serving fabric and have us help operate it. The minimum bar is straightforward: at least H100-class GPUs (or equivalent capability), and preferably four or more per machine.
Below that threshold the choice of models we can usefully serve narrows considerably. There are, in fact, two binding constraints. The first is hardware FP8 support, which is effectively a precondition for serving any of the modern open-weights models at production quality — the H100 is the first generation of NVIDIA accelerators to provide it natively, and anything older simply does not qualify, however generous its memory or however lovingly it has been maintained. The second is aggregate memory: most of the modern models worth running — Kimi, GLM, DeepSeek, the larger Qwen variants — require something on the order of 500 GB of GPU memory to load in production-grade quantization, and four H100-class accelerators is roughly the minimum that gets one there. Below either threshold, one is restricted to a handful of smaller models, and the operational case for joining the fabric weakens accordingly. Above both, we can typically find an arrangement that works for everyone involved: integration into the serving fabric we operate within e-INFRA CZ, optional dedicated allocation for the contributing group, and surplus capacity returned to the shared pool.
The details vary; the principle does not. Inquire, and we shall be pleased to discuss the matter over the appropriate beverage.
IX. Onward
The first hundred billion tokens were the difficult ones. The next hundred billion will, with any luck, be merely interesting.
We extend our thanks to the users whose appetite — agentic, conversational, and otherwise — made the milestone possible, and to the institutions whose patience made the operation viable in the first place. We look forward to DeepSeek V4 Pro, to whatever Kimi and GLM produce next, to fewer parser bugs, and to whatever the next dispatch finds worth reporting. There will, almost certainly, be something.
The hardware is on premises. The data does not leave. The models, however foreign their training, run under our roof and our rules. And the books, read from the correct ledger, are in remarkably good order.
The establishment remains open. The kettle is on. The GPUs are warm.
— Lukáš Hejtmánek, CERIT-SC, e-INFRA CZ