Documentation chatbot
Posted on November 27, 2025 (Last modified on January 30, 2026) • 9 min read • 1,714 wordsNew chatbot that answers based on CERIT-SC documentation
Chatbot on CERIT-SC documentation
We created a new chatbot that can use CERIT-SC documentation for answering questions. Along with fulltext search, the chatbot should improve user’s experience and help with understanding of the services described in documentation, supporting both English and Czech languages.
Previous work
In this article, we introduced testing of different embedders for retrieval (find relevant document to a given query). Our conclusions were:
- longer, more specific questions helped with finding the right documents
- which embedders are suitable for our purposes (language, cost)
- when language detection improves retrieval results
Now we introduce our further work, leading to a working chatbot, that can read our documentation before answering, and therefore give more context-aware and precise responses.
Behind the scenes: from question to answer
The core is implemented in LlamaIndex, which is an open-source framework that helps build LLM applications by simplifying how data is organized and used in Retrieval-Augmented Generation (RAG) systems. Llamaindex works in modular “boxes,” that can be reorganized, extended or finetuned - that is great, as it will enable and simplify future extension or modification, like switching between models, changing parameters and whole pipeline flow.
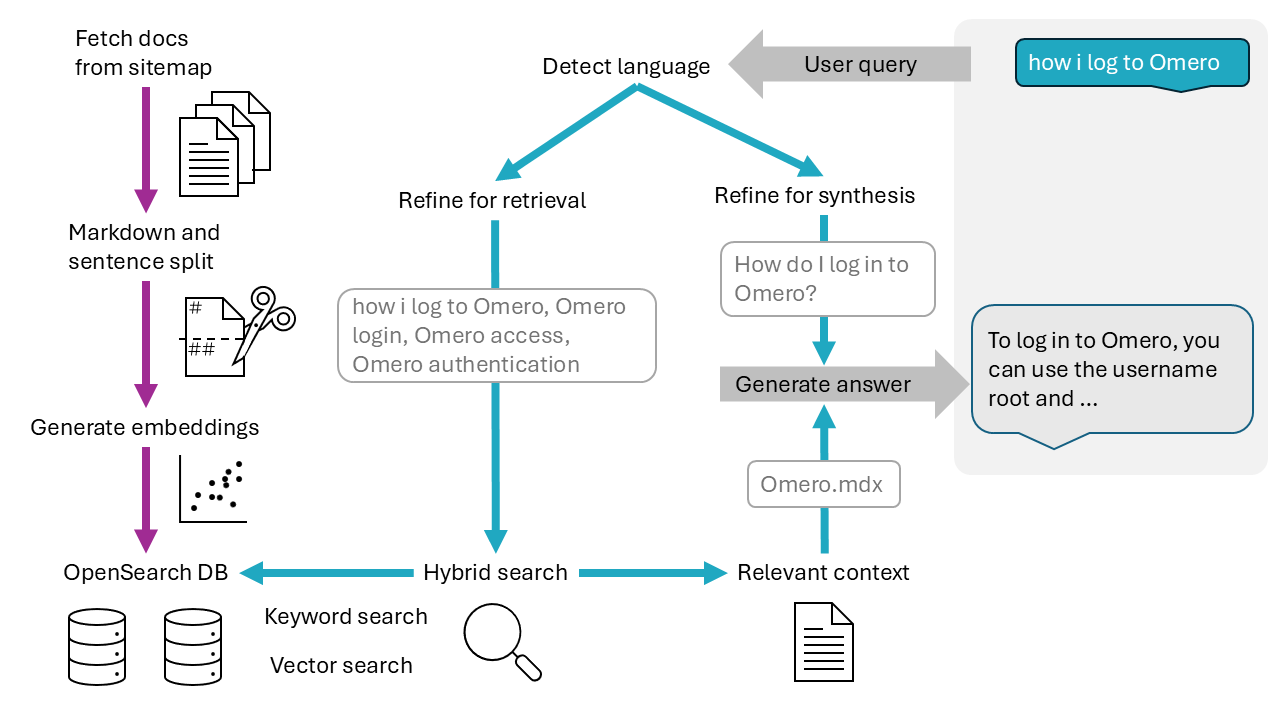
When the user types in the query, it is further processed, enhanced and used for retrieval in the documentation. In the end, the chatbot answers. The user is happy. Below the diagram, we describe the newly implemented pipeline step by step.
(Re)Load all documents
All documents are discarded and loaded new using the sitemap of e-infra documentation ( https://docs.cerit.io/en/sitemap). Then, documents are split to smaller chunks by MarkdownSplitter, which takes into account markdown headings - the docs are divided into logical parts, which avoids cutting the document in the middle of a compact part. If the resulting pieces are too big, sentence split is used. These chunks are embedded (converted to vectors) and saved into an OpenSeach database along with raw text and metadata like filename, URL, language etc. Chunk length is also a tunable parameter
Detect language (czech/english)
Using the langdetect library, this simply adds a tag cs or en to user’s query. From that point on, everything (system prompts, retrieval) becomes language-specific. Why is this important? Imagine the question is in Czech and the context is in English — the LLM would then be confused about which language to use for the answer, and might even mix them together.
Refine question for retrieval
In order to improve the retrieval, another LLM generates possible keywords to improve the lexical part of the search. The output can be balanced by setting LLM temperature - the lower the temperature, the more predictable the model is. High temperature enables more “creativity,” which in this case is not desirable. Refining means contacting another LLM with something like this:
Generate keywords that can help finding relevant documents for the question. Omit phrases like "Here is your question".
Return only this format and nothing more: Question, keyword1, keyword2."""Retrieve context
Choose top 5 most relevant documents to user’s query. During our testing, usually only one or two most relevant documents were retrieved. This is good, as the chatbot is less likely to hallucinate, than if more context was retrieved. We use hybrid search, which combines results from lexical retrieval (keyword, BM25), and from vector retrieval (KNN search). The weighted importance of keyword/vector can be set.
Refine question for synthesizer
Answers are much better when we have longer and specific question. If the user is very brief, another LLM tries to “guess” the intention and rewrite the query to be more concise. Low-temperature LLM gets instructions:
Rewrite, don’t answer.
If pronouns are used, replace them with explicit entities if implied by the question.
Do not add any intentions; only rephrase for clarity.
If the question is already clear, return it unchanged.
Return only the rewritten question and nothing else. No prefix or any suffix."""Synthesize answer
Finally, an answer is generated based on refined query for synthesis, retrieved context and system prompt:
You are a question-answering assistant, providing answers about documentation of einfra.cz organization.
Answer the QUESTION below using the information provided parts of the DOCUMENTATION.
Rules:
• If the QUESTION cannot be answered without providing false information or non-existent sources,
provide at least partial information based on the context, and answer "I don't know" for the rest.
• If any part of the DOCUMENTATION is irrelevant to the QUESTION, use only the relevant parts.
• Respond in a way that is useful and informative to the user. Be concise and clear. Provide details and argue your answer when appropriate.
• If the question is basic, assume the user has no prior knowledge and explain concepts simply.
• Preserve numbers, units, names and dates exactly as they appear in DOCUMENTATION.
<DOCUMENTATION>
{context_str}
</DOCUMENTATION>
<QUESTION>
{query_str}
</QUESTION>Cite sources
To the end of generated answer we manually add markdown links to sources of provided context, so the user can check the documentation on his/her own. It is better than relying on chatbot, because in the links cannot be any typo and in some cases the chatbot made up non-existing links.
How do we evaluate the answers?
Methodology
Previously, we evaluated only retrieval. Now it was time to improve chatbot’s answers alone. But how? Turns out that chatbot not only generates answers, but is also quite good at evaluating text quality. It is easier to critique than create - this is valid for humans and for chatbots as well. Therefore, we can ask LLM to assess another LLM’s answer.
We implemented this by using Evidently AI library. Check their blog for more info about the concept of LLM judge.

We used the same custom-made questions dataset like before, containing 4 types of variously complete questions in czech and english. Each question was generated based on one ground truth document - so we could evaluate the retrieval.
| Variant | Czech | English |
|---|---|---|
| 1 | Jakým způsobem je možné nasadit databázi Postgres pro aplikaci Omero v Kubernetes? | How do you create a secret for the Postgres database user and password for Omero? |
| 2 | Jaké jsou dvě hlavní komponenty potřebné pro spuštění aplikace Omero v Kubernetes? | Why is the second option of running Omero images manually preferred for Kubernetes over using docker-compose? |
| 3 | Co dělat, když je databáze pomalá při zpracování zátěže? | Postgres random password vs explicit password? |
| 4 | omero web ingress konfigurace | omero docker options |
Metrics
For us, the most important is avoiding hallucination and not omitting any important information provided in the documentation, and to answer in the same language like question asked. In Evidently, there are methods implementing the first two:
An unfaithful RESPONSE is any RESPONSE that:
- Contradicts the information provided in the SOURCE.
- Adds new information that is not present in the SOURCE.
- Provides a RESPONSE that is not grounded in the SOURCE, unless it is a refusal to answer or a clarifying question.
A faithful RESPONSE is a RESPONSE that:
- Accurately uses information from the SOURCE, even if only partially.
- Declines to answer when the SOURCE does not provide enough information.
- Asks a clarifying question when needed instead of making unsupported assumptions. An OUTPUT is complete if:
- It includes all relevant facts and details from the SOURCE.
- It does not omit key information necessary for a full understanding of the response.
- It preserves the structure and intent of the SOURCE while ensuring all critical elements are covered.
An OUTPUT is incomplete if:
- It is missing key facts or details present in the SOURCE.
- It omits context that is necessary for a full and accurate response.
- It shortens or summarizes the SOURCE in a way that leads to loss of essential information. We also added custom metrics for language match, using again the langdetect library.
Each answer was labeled complete/incomplete, faithful/unfaithful and same language/different language. For each combination we measured
Results
We compared our newly created pipeline with Jarvis - former chatbot that was used for searching in the documentation, but which did not work well - for example, it had only English documentation available, answered partially or sometimes hallucinated. In this graph, we can see the overall percentage of questions (both languages, all versions) that were complete/incomplete and faithful/unfaithful. There is huge improvement. However, we need to have in mind that this evaluation is still stochastic, and that there was an LLM behind these conclusions.
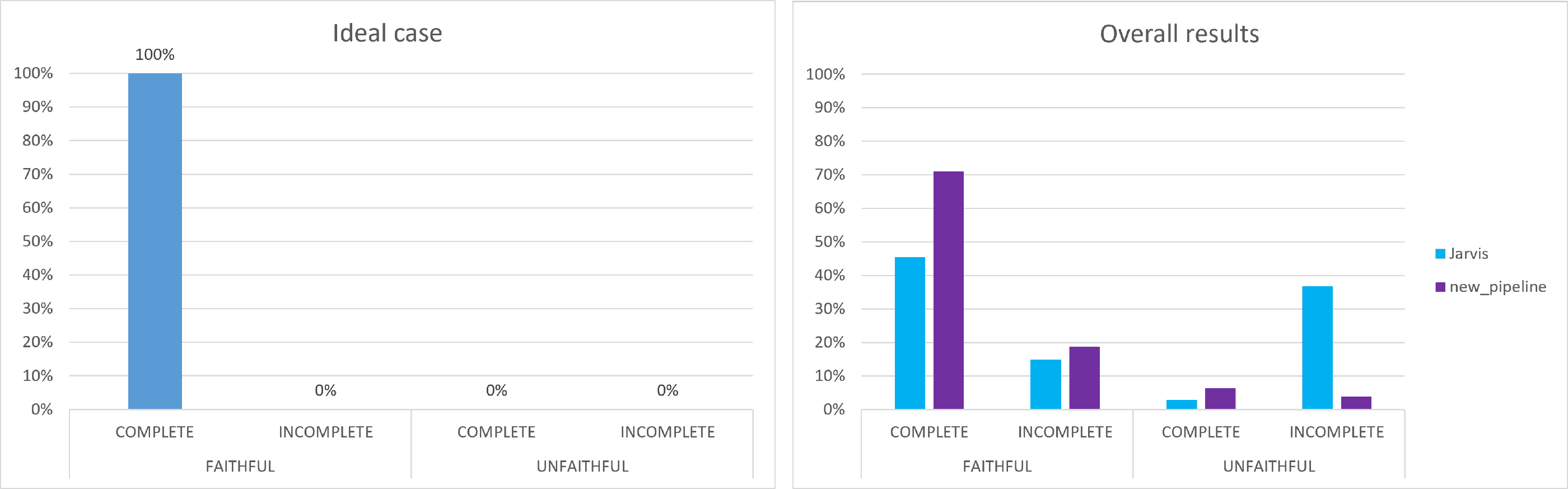
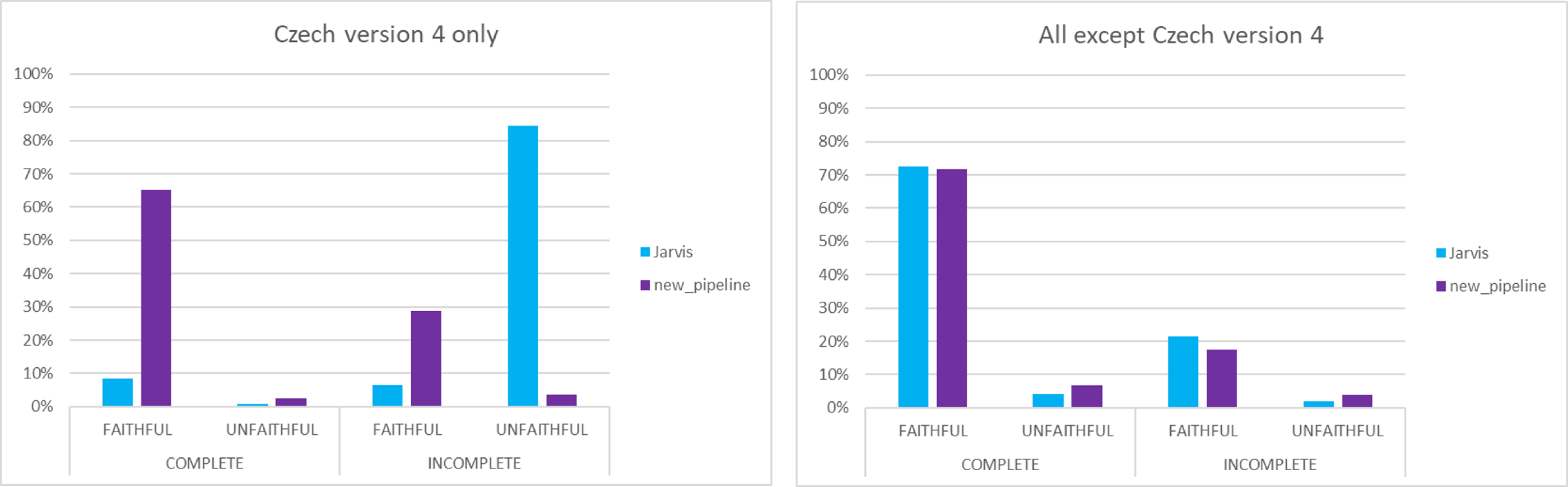
However, when checking the results in detail, we see that this “improvement” is caused only by incomplete Czech questions. This means our solution improved the result a lot in terms of this type of questions, and is comparable to original Jarvis in the rest of usecases.
Retrieval was improved a lot with Mean Reciprocal Rank reaching to 100 % in our test data, probably because of the new keywords added and better chunking strategy. Our new chatbot is also much better in language alignment: in 97 % of cases it responds in the same language like the question asked, which is both convenient for the user and possibly helpful if working with chat history.

Want to try it?
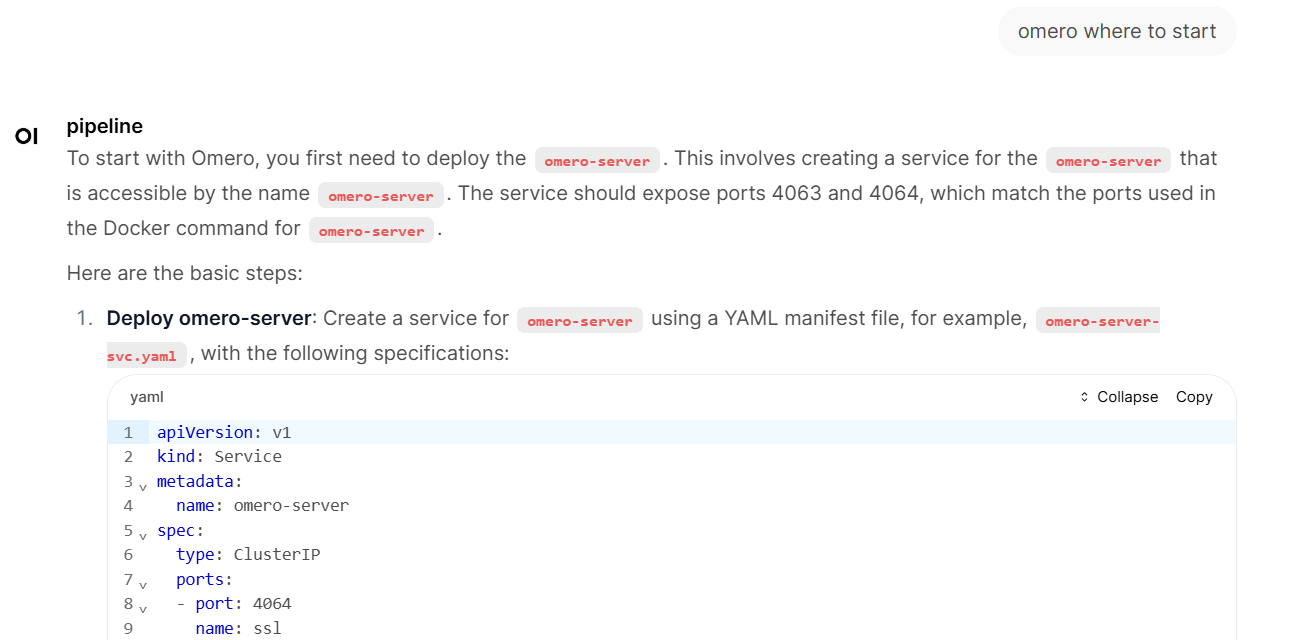
By now (24.11.2025), the chatbot is implemented under the name “pipeline” at ( https://chat-dev.ai.e-infra.cz/), where you can try it. It will soon be directly in the documentation at ( https://docs.cerit.io/)
Conclusion
The new chatbot significantly improves how users interact with CERIT-SC documentation. By combining language detection, refined retrieval, and context-aware answer generation, it provides more accurate, complete, and language-aligned responses than the previous version. Because it’s built with separate LlamaIndex parts, we can fine‑tune it or add new functions quickly, setting a strong base for future improvements.
What next?
This is just the beginning. To continue, we can change and possibly improve the pipeline in many ways like:
- add chat history,
- make the chatbot ask additional question (Do you mean rather X or Y? Should I focus on Z?) before running the retrieval,
- iteratively improve chabot’s answers,
- add user tags (expert/beginner) to personalize the expertise level,
- switch LLMs (e. g. gpt-4.1 instead of current llama-4-scout-17b-16e-instruct),
- switch embedder (currently qwen3-embedding-4b),
- experiment with order of steps in the pipeline,
- experiment with retrieval weights and algorithms
Finally, when the chatbot is implemented, we can work with real data and react on actual users’ questions.